Projet #1 – Supervision Android (FR)
Bonjour à tous, nous allons voir ensemble comment mettre en place une collecte du trafic réseau de vos appareils Android. Le but est de vous montrer les capacités des différents blocs qui seront utilisés dans l’architecture de collecte pour que vous puissiez les ajuster selon vos besoins.
Rentrons maintenant dans le cœur du sujet, les appareils portables tel que les smartphones sont de plus en plus utilisés pour les tâches du quotidien mais paradoxalement ce sont les derniers pour lesquels la supervision “classique” est mise en place. En effet, là où vous pouvez retrouver des sondes de tous types sur PC, très peu d’applications fournissent un travail similaire. Bien entendu, les acteurs majeurs, tel que Microsoft, Google, ont pris les devants avec des solutions cloud, mais le plus souvent ces solutions sont axées aux professionnels et vous n’avez que très peu de visibilité sur ce qui est fait.
C’est donc pour cela que j’ai creusé le sujet pour voir ce qu’il était possible de faire sur ces petits appareils à la fois si puissants mais tellement exposés. Etant donné que la plupart des smartphones sont majoritairement basés sur un noyau Linux, il est donc normal de penser que ce que l’on peut faire sur un serveur Linux peut être répliqué sur un smartphone. Seulement, nous faisons face ici une autre problématique : le rootage de son téléphone, puisqu’avec tous les droits sur son appareil il est bien entendu possible de faire tout ce que l’on souhaite avec. Seulement l’objectif ici est de déformer au minimum la configuration ainsi que l’intégrité du téléphone.
Après plusieurs recherches je suis tombé sur cette application : https://emanuele-f.github.io/PCAPdroid/. La documentation explique que l’application est en mesure de capturer le trafic mais également de pouvoir l’envoyer vers un serveur distant. C’est parfait pour notre supervision maison avec notre QRadar CE en réception des logs.
Il faut garder en tête que ce choix implique que la supervision ne se fait que sur la partie échange avec internet, mais, quand on y pense, cela permet de couvrir un grand nombre de scenarii basiques tels que l’accès à un site malveillant par exemple.
- Présentation du projet
- Premiers tests
- Architecture finale
- Configuration du serveur de rebond
- Configuration QRadar
- Conclusion
- Bibliographie

2. Premiers tests
Maintenant que nous avons trouvé la solution, il va falloir la mettre en place sur un téléphone et valider que nous recevons bien les logs sur notre QRadar CE. Pour cela il y a quelques prérequis à mettre en place :
- Le port 514 (ou un autre si votre configuration est différente) de votre QRadar CE doit être accessible par votre téléphone. Le plus simple, mais ce n’est pas le plus sécurisé, est de l’exposer avec un NAT sur une IP publique que vous possédez dans le cas où votre QRadar ne possède pas d’adresse IP publique.
- Vous devez avoir un téléphone sur lequel installer l’application, avec des droits suffisants pour modifier les paramètres VPN & certificats notamment
Une fois que nous avons installé l’application (cf la capture Playstore), il faut la configurer pour tester nos premiers envois de logs.
La partie de présentation de l’application peut être passée et il faut aller dans les paramètres pour configurer les champs suivants :
- “Adresse IP du collecteur” = l’adresse IP de votre collecteur QRadar
- “Port du collecteur” = le port de réception des logs sur votre QRadar (ie : 514)
- “Payload complet” : à activer, pour avoir un maximum de verbosité
- [OPTIONNEL] “Lancer au démarrage” : à activer, pour avoir un maximum de verbosité
- “Méta-données PCAPdroid” : à activer, pour avoir un maximum de verbosité
Ensuite, nous allons activer le “Décryptage TLS“, ce qui va nous permettre de déchiffrer les flux pour avoir toutes les informations pouvant être nécessaires à la détection. L’activation de cette option déclenche le wizard “Assistance de configuration Mitm” :
- Etape 1 : cliquer sur “Suivant“
- Etape 2 : cliquer sur “Installer“, puis sélectionner votre navigateur (Chrome, Firefox par exemple)
- Valider le téléchargement
- Cliquer sur le fichier téléchargé puis lancer l’installation
- Revenir sur l’application “PCAPdroid” puis cliquer sur “Suivant“
- Etape 3 : cliquer sur “Configurer” puis cliquer “Autoriser” pour les différentes autorisations demandées
- Etape 4 : cliquer sur “Exporter” et enregistrer le fichier dans vos “Téléchargements” par exemple
- Ouvrir les paramètres de votre téléphone et rechercher “Certificats CA” puis cliquer sur le paramètre en question et procéder à l’installation en choisissant le fichier que vous venez d’enregistrer à l’étape 4
- Retourner sur l’application et vous devez avoir le message “Le certificat CA est installé” désormais, cliquer sur “Suivant“
- Etape 5 : cliquer sur “Terminé“
Si vous voulez en apprendre plus sur le processus, je vous invite à lire la documentation de l’éditeur de l’application qui est très bien faite : https://emanuele-f.github.io/PCAPdroid/tls_decryption.
Une fois que tous les paramètres sont configurés, nous pouvons activer la capture du trafic en cliquant sur le bouton “Play” en haut à droite de l’application.
Malheureusement côté QRadar, des logs arrivent bien mais ils ne sont pas “compréhensibles”, c’est assez logique puisque l’application envoie les flux en brut sans faire de traitement, ce qui fait que QRadar n’est pas en mesure de faire l’extraction correctement. C’est donc pour cela qu’il faut se tourner vers le script : https://github.com/emanuele-f/PCAPdroid/blob/master/tools/udp_receiver.py pour faire l’extraction des trames réseaux.
2. Architecture finale
Nous allons maintenant tester le script mentionné juste avant, ce script permet d’extraire les flux bruts et de les déchiffrer en trames lisibles. Ce script sera exécuté sur un serveur de rebond pour éviter tout impact sur le QRadar. L’objectif ensuite est d’envoyer ces trames à QRadar pour qu’il considère cela comme des flux similaires à ce que l’on retrouve pour un pare-feu. Dans la documentation de l’éditeur on trouve les lignes suivantes en exemple :
python3 /root/prod/qradar/udp_receiver.py -p 1234 | tcpdump -w dump.pcap -r -Dans l’exemple, le port 1234 est le port d’écoute du script, cela signifie qu’il va déchiffrer tout ce qu’il arrive sur ce port. Ce qui va être déchiffré est envoyé dans un tcpdump via le standard input (d’où le “-“) qui va écrire dans un fichier le résultat.
-r file
Read packets from file (which was created with the -w option or by other tools that write pcap or pcapng files). Standard input is used if file is “-“.
https://www.tcpdump.org/manpages/tcpdump.1.html
Ainsi en configurant dans l’application l’adresse de la machine qui exécute le script ainsi que le port configuré dans la ligne de commande, nous récupérons les échanges dans le fichier. Ensuite, le challenge est d’envoyer le tout à QRadar, pour ce faire,il faut dans un premier temps que chaque flux corresponde à une ligne du tcpdump, en vérifiant nous obtenons des logs similaires à ceux ci-dessous.
19:03:42.458240 IP 10.215.173.1.34966 > com.elgoog.fr.https: Flags [P.], seq 6431:7107, ack 45639, win 1514, length 676Maintenant, nous souhaitons que l’adresse IP soit mise à la place des FQDN, pour cela il nous faut utiliser l’option “-n”. De plus, pour s’assurer qu’il n’y a pas d’éventuel troncature du paquet, nous mettons la taille de capture par paquet au maximum avec l’option “-s0”.
-n
Don’t convert addresses (i.e., host addresses, port numbers, etc.) to names.
[…]
-s snaplen
--snapshot-length=snaplen
Snarf snaplen bytes of data from each packet rather than the default of 262144 bytes. Packets truncated because of a limited snapshot are indicated in the output with “[|proto]”, where proto is the name of the protocol level at which the truncation has occurred.
Note that taking larger snapshots both increases the amount of time it takes to process packets and, effectively, decreases the amount of packet buffering. This may cause packets to be lost. Note also that taking smaller snapshots will discard data from protocols above the transport layer, which loses information that may be important. NFS and AFS requests and replies, for example, are very large, and much of the detail won’t be available if a too-short snapshot length is selected.
If you need to reduce the snapshot size below the default, you should limit snaplen to the smallest number that will capture the protocol information you’re interested in. Setting snaplen to 0 sets it to the default of 262144, for backwards compatibility with recent older versions of tcpdump.
https://www.tcpdump.org/manpages/tcpdump.1.html
On obtient ainsi la ligne de commande de capture suivante :
python3 /root/prod/qradar/udp_receiver.py -p 2101 | tcpdump -ns0 -r -Enfin, il faut envoyer le résultat sur le QRadar, pour ce faire nous allons utiliser le service rsyslog de Linux qui permet d’envoyer des logs système ou encore des logs issus d’un fichier vers des serveurs distants. Nous verrons plus en détail dans la section sur la configuration du rsyslog comment faire.
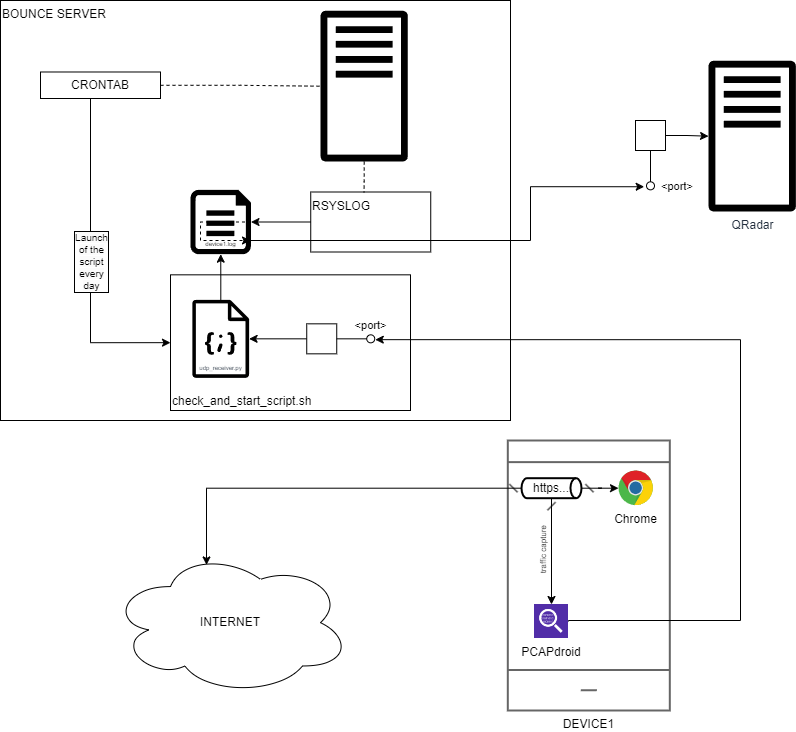
En résumé, nous obtenons l’architecture suivante :
J’ai également rajouté dans l’architecture un script qui permet de faire la vérification que tout fonctionne correctement, cela permet de s’assurer du bon fonctionnement de la collecte tout en la redémarrant proprement en cas de problème. De plus, il y a également une configuration sur la rétention des logs à faire pour éviter le remplissage de vos disques, cela peut se faire facilement avec la fonctionnalité native logrotate.
4. Configuration du serveur de rebond
Pour le serveur de rebond, nous avons 3 parties majeures à configurer :
- crontab : pour exécuter régulièrement le script de vérification du système de collecte
- rsyslog : pour envoyer les logs vers le serveur QRadar
- logrotate : pour s’assurer de la rétention des logs sur le serveur de rebond ainsi que de la purge des logs les plus anciens
Remarque : Cette configuration peut paraître lourde mais elle permet de s’assurer de la pérennité de la collecte de manière autonome, grâce à plusieurs script d’automatisation. Il est important de garder en tête que le temps pris à faire ces actions permet de gagner beaucoup de temps de maintenance mais également d’en apprendre un peu plus sur les services de base d’un Linux tels que rsyslog ou encore logrotate.
4.1 Crontab
La configuration crontab mise en place est la suivante :
0 0 * * * /path/to/script/check_and_start_script.sh >/dev/null 2>&1Cette configuration va exécuter le script tous les jours à minuit. En regardant le script de vérification, il s’agit d’un test conditionnel vérifiant s’il y a le port de collecte qui est utilisé par le script de collecte ou non. S’il est utilisé, cela signifie que la collecte est en cours et fonctionnelle, s’il n’est pas utilisé, le script va la redémarrer.
#!/bin/bash
Check if the Python script is running for device 1
if pgrep -f "/root/prod/qradar/udp_receiver.py -p 5555" >/dev/null; then
echo "Python script for device 1 is already running."
else
echo "Python script for device 1 is not running. Starting..."
Start the Python script
python3 /root/prod/qradar/udp_receiver.py -p 5555 | tcpdump -ns0 -r - > /var/log/qradar/device1.log &
fi
4.2 Rsyslog
La configuration rsyslog mise en place est la suivante :
module(load="imfile" PollingInterval="10")
input(type="imfile"
File="/var/log/qradar/device1.log"
Tag="device1"
Severity="info"
Facility="local0")
local0.* @@<QRADAR_IP>:<QRADAR_PORT>
Il faut bien penser à remplacer dans la configuration :
- <QRADAR_IP> : avec l’IP de votre QRadar
- <QRADAR_PORT> : avec le port de votre QRadar
Il est préférable d’enregistrer votre fichier de configuration dans le dossier /etc/rsyslog.d/qradar.conf et ainsi avoir un fichier de configuration dédié à cette collecte. Une fois le fichier enregistré, il faut redémarrer le service pour appliquer les changements.
4.3 Logrotate
La configuration logrotate mise en place est la suivante :
/var/log/qradar/device1.log {
size 10M
create
rotate 7
missingok
notifempty
prerotate
/root/prod/qradar/prerotate_script.sh 5555
endscript
postrotate
/root/prod/qradar/check_and_start_script.sh
endscript
}La configuration permet de garder 7 fichiers de 10M au maximum. Il y a également un script qui est exécuté avant la rotation du fichier ainsi qu’un script exécuté après la rotation du fichier. En effet, le premier script arrête le déchiffrement et donc le blocage du fichier de log. Ensuite, le deuxième script permet de relancer la collecte.
Tout comme le service rsyslog, il est préférable de faire un fichier de configuration dédié dans /etc/logrotate.d/qradar.conf puis de redémarrer le service pour appliquer la configuration.
5. Configuration QRadar
Nous avons désormais construit une grande partie de la collecte, il ne nous reste plus qu’à faire la configuration sur ce qui va réceptionner les logs, ici QRadar. Vous pouvez tout à fait envoyer les logs dans un puits de logs ou un autre outil selon vos besoins. Dans le cas présent nous verrons quelques particularités en rapport avec QRadar.
En effet, nous avons vu dans l’architecture ci-dessus que nous avions une configuration rsyslog pour chaque appareil que nous souhaitions superviser, mais le tout est envoyé depuis la même machine de rebond vers le QRadar. Cela a pour conséquence que QRadar ne va pas être en mesure de faire la différence entre tel ou tel appareil d’un point de vue source d’évènements. C’est ainsi qu’il faut utiliser d’une fonctionnalité appelée “Log Source Gateway” pour réussir à avoir plusieurs sources d’évènements tout en gardant qu’un seul serveur de rebond. De plus nous verrons que cette méthode offre une meilleure scalabilité si vous souhaitez rajouter des appareils en supervision par la suite.
5.1 Log source gateway
Avant de rentrer dans le vif de la configuration voici la vue macro de ce que nous souhaitons faire :
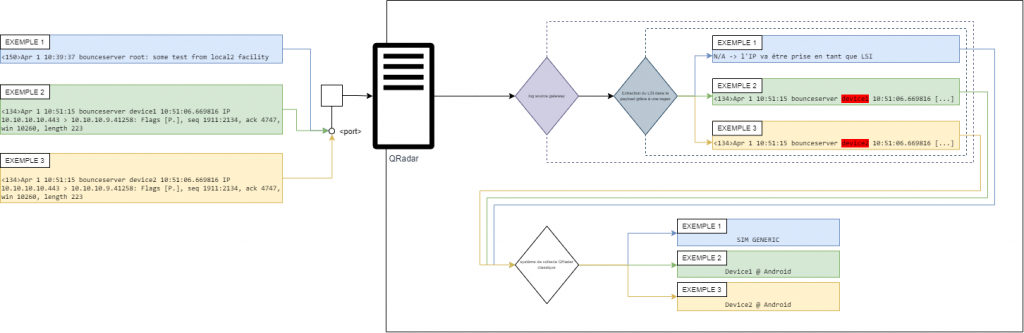
Ce schéma est simplifié puisque l’on part du principe que les log sources pour les différents appareils ont déjà été créées, sinon il y a le processus de détection automatique de log source qui rentre en jeu notamment.
Pour la partie configuration de la log source gateway, nous avons besoin de 2 paramètres importants :
- un port de réception des logs en entrée du QRadar
- une regex pour extraire le Log Source Identifier (LSI) des évènements arrivant sur le port précédemment défini
Ce type de log source fonctionne ainsi car QRadar a besoin de faire un travail différent de celui fait habituellement si on lui envoie un évènement sur le port 514 par exemple. Par défaut si vous n’avez pas configuré d’autre log source gateway, QRadar va vous proposer d’utiliser le port 517, vous pouvez très bien garder ce port ou en utiliser un autre mais il faut bien faire attention à ce que ce port ne soit pas utilisé par QRadar, pour cela une vérification rapide peut être faire en ligne de commande sur la console.
[root@qradar01 ~]# netstat -plan | grep LISTEN | grep 517
tcp6 0 0 :::517 :::* LISTEN 75141/javaDans le cas présent, je ne peux pas utiliser le port 517 car il est déjà utilisé par QRadar pour la collecte, si je change le port 517 dans la commande par 518 et que je n’obtiens pas de retour alors cela signifie que le port est disponible.
Pour le deuxième paramètre, il faut prendre un évènement reçu par QRadar pour voir où est-ce que le LSI que je souhaite extraire se situe. Par exemple si on reprend les exemples du schéma ci-dessous :
<134>Apr 1 10:51:15 bounceserver device1 10:51:06.669816 IP 10.10.10.10.443 > 10.10.10.9.41258: Flags [P.], seq 1911:2134, ack 4747, win 10260, length 223Je souhaite extraire la partie “device1” de cet évènement, sans rentrer dans les détails de la regex que j’ai choisi je vais surtout vous expliquer la meilleure approche à avoir pour obtenir une regex des plus optimales et donc qui impactera au minimum votre infrastructure QRadar. Dans un premier temps, il est intéressant de récupérer un échantillon de 50 évènements au moins, tous différents pour se rapprocher des conditions réelles. Ensuite, vous utilisez un outil de vérification de regex tel que regex101, le point fort de cet outil est qu’il propose un retour sur le nombre d’étapes de calcul pour obtenir les résultats, c’est ce chiffre qui va nous intéresser tout particulièrement.
Par exemple si je prends mon expression, j’obtiens 190 étapes pour le calcul de 10 évènements.

Par contre si j’utilise des filtrages plus “greedy” tels que le “.*” pour matcher n’importe quel caractère de 0 à n fois, j’obtiens un résultat beaucoup plus grand : 1710 étapes.

Dans les 2 cas, j’ai bel et bien 10 matchs donc cela signifie que ma regex fonctionne correctement mais le nombre d’étapes est presque 10 fois plus important d’une regex à l’autre. C’est donc pour cela que j’opte pour la première expression.
Remarque : Bien entendu, il y a très certainement des expressions encore plus performantes mais il faut savoir trouver l’équilibre entre une expression performante et qui fonctionne également.
Une fois les 2 paramètres configurés, je peux sauvegarder ma log source gateway et effectuer un déploiement pour appliquer les changements et surtout indiquer à QRadar qu’il doit écouter sur le port 518 dans le cas où on choisit ce port.
5.2 DSM Custom
Nous avons donc franchi l’étape de récupération des évènements et de l’acheminement vers une log source précise mais maintenant il faut faire en sorte que ce que contient un évènement est bien compris par QRadar. Pour cela il faut passer par l’étape du parsing/mapping dont j’ai déjà parlé dans l’article suivant : https://staze.fr/collecte-de-logs-synology-partie-2/.
Je ne vais pas revenir sur la procédure en détail mais si vous devez retenir 4 points, ce sont les suivants :
- Pour que QRadar récupère les différentes parties d’un log pour les associer à des propriétés, il faut un bon parsing
- Pour que QRadar catégorise correctement un log grâce à une paire de propriétés que sont l’ID et la catégorie de l’évènement, il faut un bon mapping
- Un parsing complet n’est pas nécessaire et est très souvent contre-productif puisque cela demande un travail supplémentaire pour QRadar à chaque champ que vous souhaitez extraire. Il est donc important de ne faire que le parsing sur ce qui vous est utile
- Un mapping complet n’est pas nécessaire à une bonne qualité de logs mais il est préférable de connaître l’exhaustivité des ID/catégories des évènements qu’un équipement vous envoie pour savoir si vous ne manquez pas des évènements importants à catégoriser
Dans notre cas, nous savons que les informations qui transitent sont des informations de flux réseaux, les points les plus importants sont donc les suivants :
- Connaître la source (IP/Port/User-Agent…)
- Connaître la destination (IP/Port/FQDN…)
- Connaître les détails de l’échange (Protocole/Utilisateur/Statut…)
Ensuite, pour ce qui est de la catégorisation, pour les flux c’est plutôt simple, soit le flux est accepté, soit il est bloqué, il faut rajouter à cela quelques cas à la marge pour certains protocoles et on obtient un DSM personnalisé qui est cohérent pour une première version. Vous trouverez ma version ici : https://github.com/staze0/QRadar/blob/main/DSM%20Custom/Custom%20TCPDump%20Netflow.zip.
5.3 Scenarii de détection
Nous avons enfin notre chaîne de collecte de bout en bout, il faut maintenant mettre à profit celle-ci grâce à des scenarii de détection axés sur ce type d’évènements. Dans un premier temps nous allons mettre en place une règle pour superviser quand un appareil accède, avec réussite ou non, à une adresse IP qui fait partie d’une liste d’adresse IP malveillantes.

Cette règle peut-être améliorée en la combinant avec le travail décrit dans la série d’article sur la CTI pour peupler automatiquement un référentiel avec des adresses IP malveillantes qui sont remontées par OpenCTI. Je vous laisse lire (ou relire) la série d’articles pour effectuer la mise en place, vous n’aurez ensuite qu’à modifier la règle décrite ci-dessus en changeant la deuxième ligne pour comparer à un référentiel.
Lien de la série d’articles : https://staze.fr/category/series/integrer-la-cti-a-qradar/
Dans un deuxième temps, vous pouvez également effectuer de la supervision sur les noms de domaine puisque nous avons les résolutions DNS dans les évènements. Pour cela il faut s’assurer que le nom de domaine est bien parsé et que l’option pour l’utilisation dans des règles est cochée, comme ci-dessous.
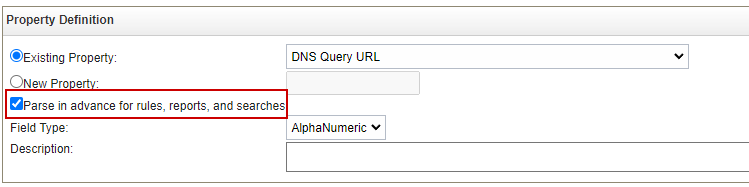
Enfin, comme pour la règle précédente, vous pouvez vous appuyer sur des référentiels publics qui sont accessibles pour peupler automatiquement des référentiels dans QRadar. Par exemple, pour les noms de domaine vous avez ce projet : https://red.flag.domains/ qui référence les TLD malveillants avec des mises à jour tous les jours.
6. Conclusion
Nous voici à la conclusion de ce projet de supervision d’appareils Android, en espérant que vous aurez découvert un maximum de choses au travers de ces différentes parties ou que cela vous aura donné des idées pour améliorer votre supervision.
N’hésitez pas à me faire des retours si vous avez des questions ou à partager votre point de vue sur ce sujet car il est certain que cette première version de supervision Android n’est pas parfaite et qu’elle ne demande qu’à être améliorée.
7. Bibliographie
- https://emanuele-f.github.io/PCAPdroid/
- https://info.techdata.com/rs/946-OMQ-360/images/Section%202%20-%20Technical%20Sales%20Foundations%20for%20IBM%20QRadar%20for%20Cloud%20%28QRoC%29V1%20P10000-017.pdf
- https://red.flag.domains/
- https://www.ssi.gouv.fr/actualite/opencti-la-solution-libre-pour-traiter-et-partager-la-connaissance-de-la-cybermenace/
- https://regex101.com/
- https://github.com/staze0/QRadar/tree/main
Merci d’avoir suivi ce petit tuto, en espérant que cela vous ait été utile. N’hésitez pas à me communiquer vos ressentis, tips…etc via le formulaire ci-dessous.